In FME 2017 we have spent a considerable amount of time improving the AWS transformers and readers/writers. Here’s an overview of the improvements.
All AWS Readers/Writers and Transformers
Regions
All AWS transformers and readers/writers now allow you to specifically define the region you are using.
Why it’s important: Better performance
This will improve performance by reducing latency. Previously all transformers and readers/writers were hardcoded to use the AWS us-east-1 region. This works even if you are not using that region because us-east-1 is special in that it forwards requests to other regions. The problem is, if you were using the Sydney region and located in Australia, then the latency going via us-east-1 could have made the request 10x slower.
You should therefore configure the transformer to use the region that your data is stored in, rather than proxying through US East. If you are unsure where the service is located, using the US East (Northern Virginia) region will still work and route the request to the right region.
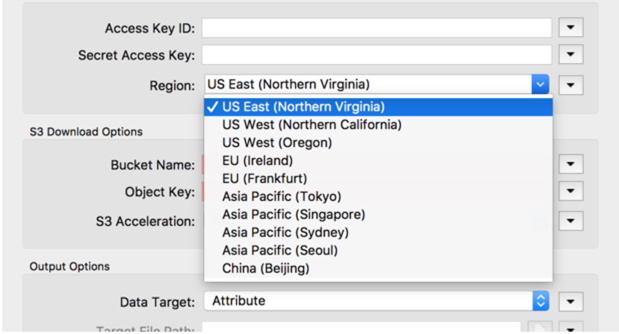
Choosing the AWS region in transformer parameters.
GovCloud
All AWS transformers/readers/writers allow you to connect to the GovCloud region.
Why it’s important: A new region
GovCloud is a special region with a different endpoint that we previously couldn’t connect to. Adding support for this means governments can use FME to interact with services on GovCloud.
Proxy Support
All AWS transformers and readers/writers now support the system proxy in FME Workbench. It was an oversight this wasn’t added initially but now if you need to go through a proxy to get to the internet it will work.
Why it’s important: Use AWS transformers behind a proxy
Previously AWS transformers and readers/writers ignored the system proxy settings. This meant if you were behind a proxy, you couldn’t use the transformers. Note, the custom proxy maps in workbench settings still do not work.
Named Connections
Support for AWS named connections has been added. Users can add an AWS named connection by providing an Access Key and Secret.
Why it’s important: Reusable connection info
The main benefit here relates to portability and reusability. Named connections allow you to create one AWS Web connection and re-use it throughout the workspace. If anything changes then you only need to update the credentials in one place. FME Server 2017 also supports web connections, ensuring you can publish and share your workflows seamlessly there.
S3Downloader
S3 Transfer Acceleration
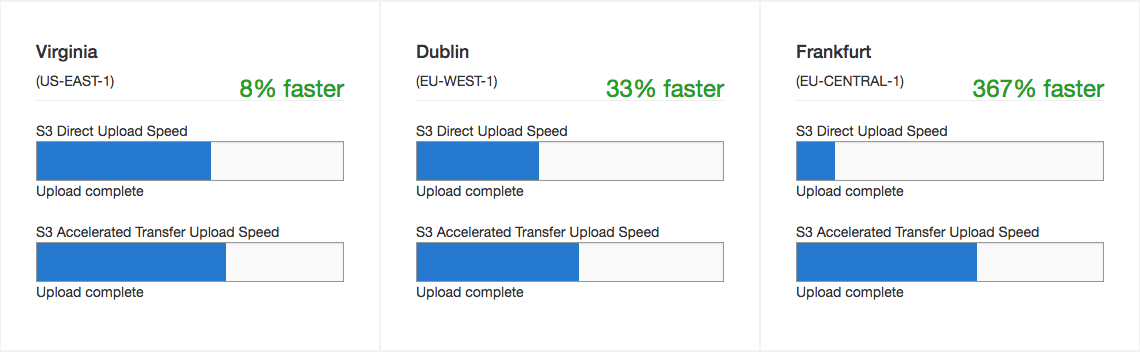
The S3 transfer acceleration is a new feature from AWS that allows you to upload and download files with increased speed. There is now a dropdown to allow you to leverage the acceleration on both the S3Downloader and S3Uploader.
Note, there are additional charges on AWS for using the transfer acceleration.
Why it’s important: Better performance
Uploading and downloading data from S3 can take a lot of time and be a bottleneck for adopting AWS. S3 transfer acceleration can increase transfer speeds between 5% and 300% depending on where you are, this could dramatically reduce the runtime of translations. You can see from the charts below, the further you are away geographically from the data centre (I am in Vancouver, Canada), the greater the performance gains.
Download File Handling
When downloading to a file that already exists, users can now select between outputting a feature (previous behaviour) via the rejected port or overwriting the file.
Why it’s important: Download a file that already exists
Previously you couldn’t download a file to a folder if it already existed. Since updating files on S3 and syncing with an on-premises file system was a common scenario, it was important to fix it.
Allow Body Encoding to be Configured
When downloading a feature from S3 to either an Attribute or File, you can now set the body encoding. The default is for the transformer to auto-detect the encoding type from the HTTP Headers.
Why it’s important: Correct file handling
Currently, clients are using the S3Downloader in combination with the AttributeEncoder to fix the issue as everything used to be treated as fme-binary. For example, previously if you uploaded a GML file to an S3 bucket, downloading it using the S3Downloader would have resulted in the GML file being encoded as fme-binary. Now the transformer will look in the HTTP headers and auto-detect the correct encoding. The content encoding can be set in the S3Uploader by using the new Header support.
S3Uploader
S3 Transfer Acceleration
The S3Uploader supports S3 transfer acceleration as mentioned above in the S3Downloader section. The benefits are the same.
Note, there are additional charges on AWS for using the transfer acceleration.
Request Headers
Previously when you uploaded to S3 you could only set one request header: content-type. You asked to be able to set other header values such as content encoding. The new UI lets you set any header defined in the AWS documentation via a key/value pair table.
Why it’s important: Flexibility
It dramatically increases the flexibility and power of the transformer. There are over 20 headers that can be set on uploading a file to S3, and this enables you to set all of them. We added the ones we see as the most important to the drop-down so you don’t need to type them: Cache-Control, Content-Disposition, Content-Encoding, Content-MD5, Expect, Expires, x-amz-meta-, x-amz-grant-read, x-amz-grant-read-acp, x-amz-grant-write-acp.
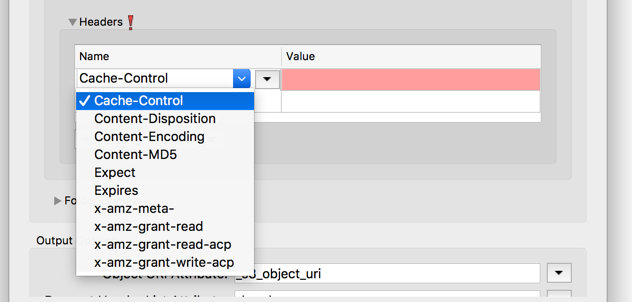
SQSReceiver
Receive Message Attributes
When using the SQSReceiver, users can now specify which messages attributes they want to receive. They can also specify “All” to receive all message attributes.
Why it’s important: Sending metadata
Message attributes are important to allow structured metadata to be sent along with the message (such as timestamps, geospatial data, signatures, and identifiers). This information can be used by the receiver of the message to help decide how to handle the message without having to first process the message body. The SQSSender can already set these attributes, so it makes sense to also allow the SQSReceiver to have access to them.
Stop When No New Messages Found
Added ability for users to stop the receiver when there are no more messages to be read. This option can be turned on or off in the transformer properties.
Why it’s important: Better automation
Previously there are two receive options for the SQSReceiver:
- Read indefinitely (Persistent Receiver: Yes)
- Read a specific number (Persistent Receiver: No)
This parameter offers a third option, read until no new messages are found.
Currently, if you don’t want your workspace to run forever (Persistent Receiver set to No), but don’t know how many messages you will actually have at runtime, you have to guess a number of messages to read. To ensure you get all of the messages, you end up specifying a much larger number just to be on the safe side. The trouble is FME spends time trying to read all messages. e.g. If you have defined 3 million records to read, but there are only 1 million messages actually in the queue, FME wastes time trying to read the 2 million extra messages.
The Stop When No Messages Found flag solves this problem. It effectively causes the transformer to connect to a queue and read until the queue is empty. Useful if you are scheduling a workspace on FME Server.
DynamoDB Reader/Writer
These features were actually included in FME 2016.1.
Secondary Indexes
Added support for secondary indexes to the DynamoDB reader and writer.
Why it’s important: Efficient data access
Secondary indexes allow efficient access to data with attributes other than the primary key. Once you have exposed the secondary index in the reader, any query request can be made against the index. Since a table can have multiple secondary indexes, it gives your applications access to many different query patterns.
You can use the DynamoDB writer to create both local and global indexes. To create the local secondary index (LSI), both the partition and sort keys must be set in the Primary key. It is the same when using the AWS console to create the LSI. LSI only can be created when creating tables. Our DynamoDB writer only supports creating one global secondary index (GSI) when creating tables. If you wish to create more than one GSI on the table you will need to use the AWS console or UI.
Query Parameters
Added full query support to the DynamoDB reader which enables specific subsets of the data to be extracted efficiently.
Why it’s important: Performance
Query parameter support is a huge deal. Without it, the reader reads in all of the data from the database—not too useful if you have millions of records in there. The reader now supports defining both a partition key value and query sort key.
Querying with just the partition key (hash attribute) value set will query records based on matches against the values in the table or secondary index (if it is set). Using the query sort key allows you to refine the search by using sort key names and values in combination with comparison operators. This gives you a much more powerful query and allows you to do things like query the Reply table for a particular Id (partition key) but return only those items whose ReplyDateTime (sort key) begins with certain characters.
AWS and FME 2017 Webinar – Your Questions Answered
Join us for a webinar where we’ll give a sneak peek at enhancements to AWS capabilities included in FME 2017. We’ll showcase new ways to integrate and leverage AWS solutions like Earth on AWS, and offer insight with a real world example.

Stewart Harper
Stewart is the Technical Director of Cloud Applications and Infrastructure at Safe. When he isn’t building location-based tools for the web, he’s probably skiing or mountain biking.



