
Elastic Processing in the Cloud with Docker and FME Server


Cloud and container technologies are key to efficiently completing compute-intensive tasks. We have been experimenting with “Elastic Processing” for large tasks that can be broken into many smaller ones.
Here’s how we used FME Server to exploit the elasticity of the cloud. Plus, see how we put it to the test and cut an 8-hour tile cache workflow down to 20 minutes.
Elastic Processing Pattern
The pattern for this workspace is very simple, with only step 3 varying with the Task being performed.
Elastic Pattern FME Workspace
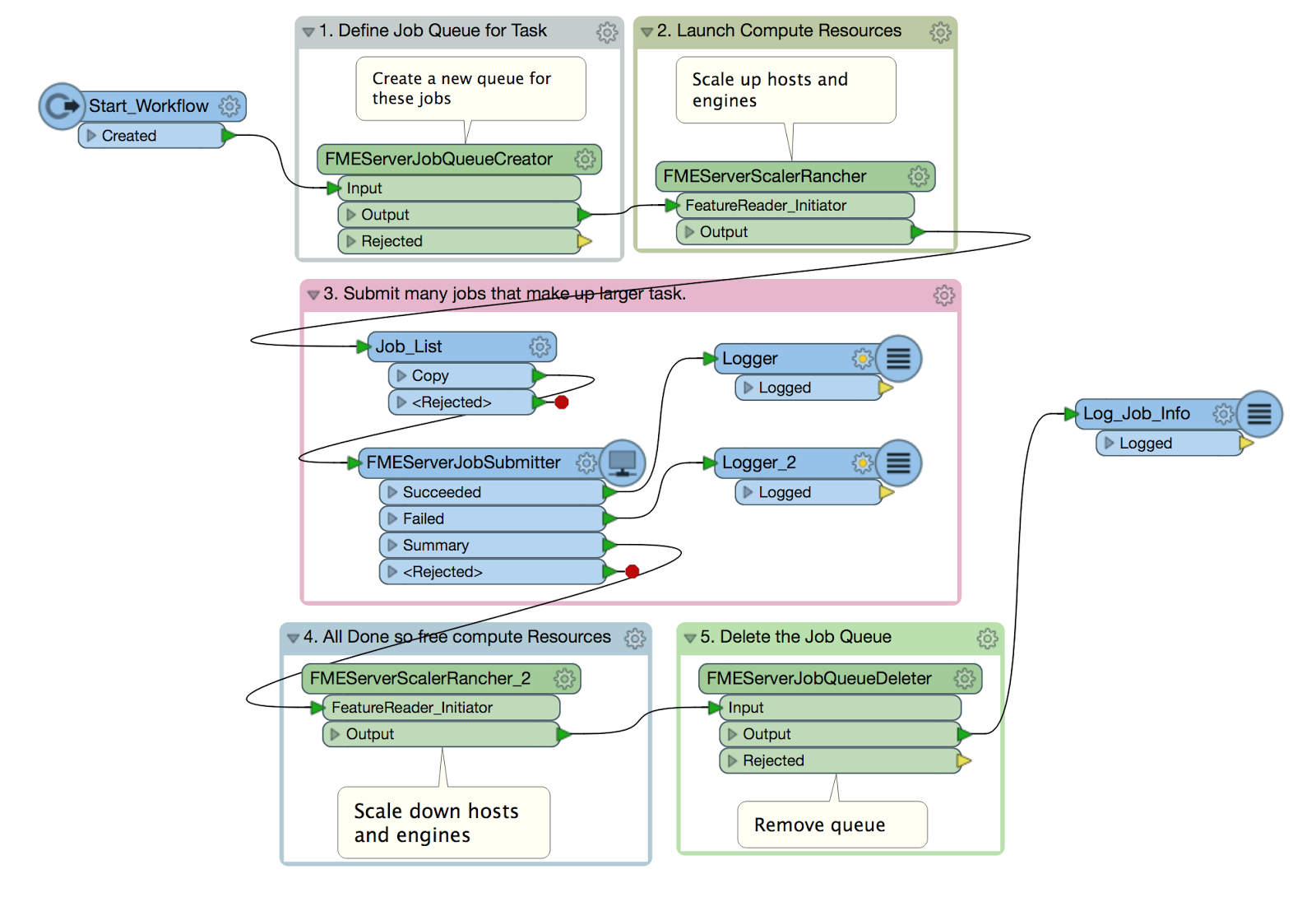
This Elastic Processing Pattern is great for tasks that can be broken down into a large number of small jobs. The pattern is as follows:
- Define the job queue. All jobs for the task will be submitted to this FME Server queue. The job queue name must be unique for the task. This is done via the FMEServerJobQueueCreator transformer on FME Hub.
- Launch Compute Resources. The number of hosts and engines to launch are specified. The job queue created in step 1 is also specified. As of FME 2018, engines can be launched with one or more job queue names specified. The engines will then only process jobs from those queues. In this workflow, we specify 1 queue. The FMEServerScalerRancher transformer launches the specified machines and engines, and returns immediately. It doesn’t have to wait for them to be launched but rather returns as soon as it can.
- Submit and Process Jobs. The jobs that make up the task are all submitted to the FME Server. Again the job queue is specified so every job goes to the job queue and is processed by one of the engines assigned to the job queue and launched in Step 2. The FMEServerJobSubmitter is set to Submit Jobs -> In Parallel and Wait for jobs to Complete-> Yes. This ensures the job waits until all jobs are complete. Note: We are not totally happy with this as we are using an engine that is waiting for the work to finish. We will address this in a future version of FME Server. 😉
- Release the Compute Resources. After the jobs are completed we immediately scale the engines again using the FMEServerScalerRancher transformer. This time we specify 0 engines and 0 machines.
- Delete the job queue. This step is not necessary but we are being nice to our server so we don’t leave unused job queues laying around. This is done via the FMEServerJobQueueDeleter transformer on FME Hub.
Supporting Technology
To make this happen, we relied on leading-edge technology upon which we are building future FME Server products.
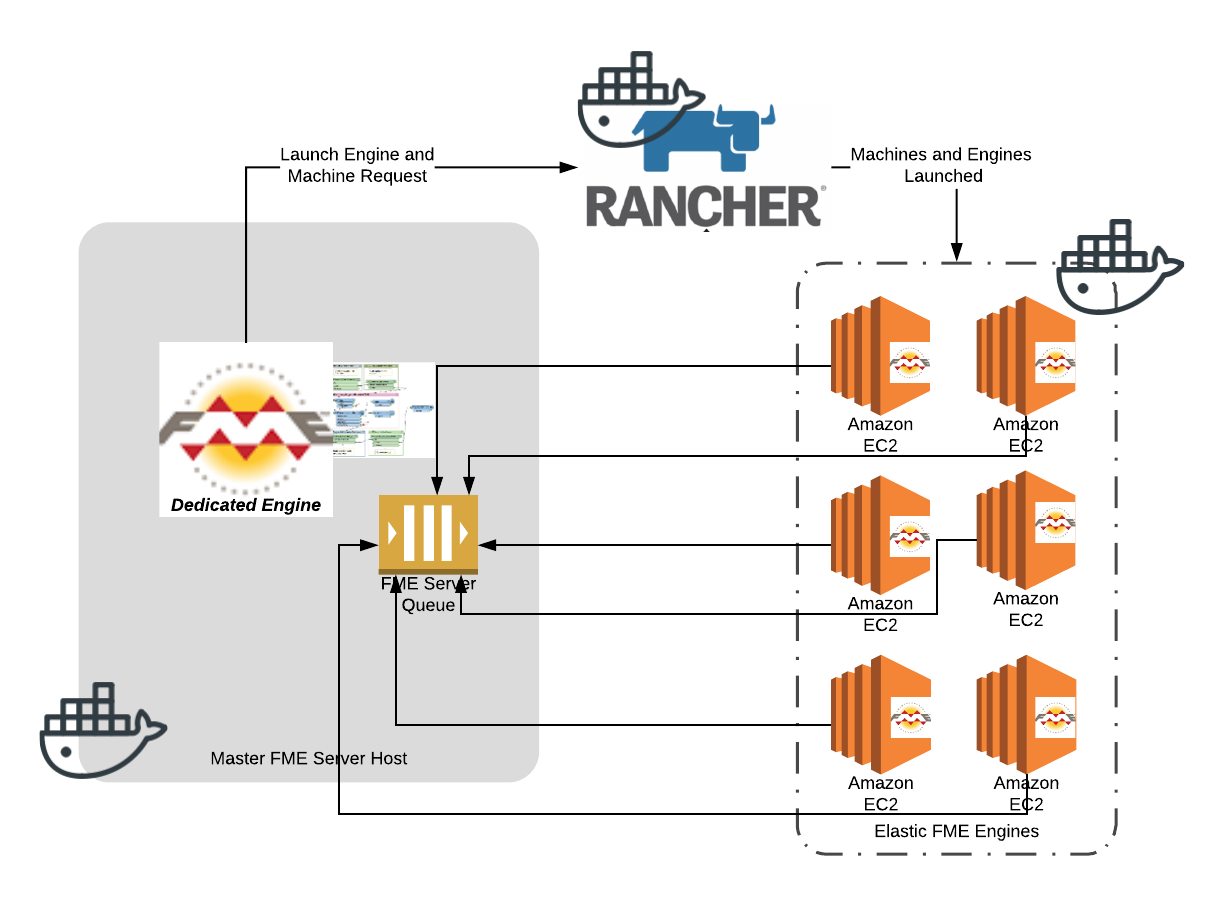
- Docker – FME Server is now deployable as a collection of containers. These containers give us the power to easily deploy FME Server in new and powerful ways, such as this pattern. Suffice it to say that containers are going to play a bigger part in FME Server’s future. In this example, all FME Server including the FME Engine components are running in Docker.
- AWS – Amazon Web Services compute instances. Here we used Amazon EC2 instances. This pattern, however, could easily be deployed on any cloud stack such as Azure or Google. Indeed we will see more cloud offerings and better container support from cloud providers.
- Rancher – Host management layer that enables us to launch new compute nodes (EC2 in this case) and also the FME Engine containers that will do the work.
- FME Server 2018 – New capabilities of FME Server 2018 help make this possible. The new job queue capability is one good example.
- FME Hub – FMEServerJobQueueCreator and FMEServerJobQueueDeleter. These two transformers make it easy to create and delete FMEServer job queues. FME Hub is in its infancy. Look for this to grow by leaps and bounds over the next year. I check this weekly and recommend you do too. Amazing how FME is being expanded by the FME community.
Watch: Elastic Processing Pattern in operation
Grant and I made a video showing this pattern in operation. You will see the Rancher interface, scaling, and the whole workflow.
Putting the Pattern to Work
Having built the technology, we didn’t have to look far for a sample Task on which to give it a try. We simply visited our local FME Scenario Guru, Dmitri. To say he was excited is an understatement. We put this to the test on generating a raster tile cache for a large area.
Large Area Raster Tile Cache Generation
Tile caches of large areas can have hundreds of thousands or even millions of tiles. Generating them is a compute-intensive task that can take days on a single machine. Running this on a desktop resulted in the machine being so slow that Dmitri couldn’t even play solitaire!
Modern imagery providers such as Planet now deliver daily updates for the entire planet. The only way to generate Tile caches in a timely way for large areas is to leverage the power of many machines.
With the technique described here, we can now use as many machines and engines as we want to process the data in a timely fashion.
In our tests, we used an RDS-based PostGIS database preloaded with the OSM datasets covering a large metropolitan area.
The tile cache for London for up to zoom level 17 consists of ~800,000 tiles, and takes well over 8 hours on a single machine. Launching 24 machines using this Elastic Pattern, we get the same result in about 20 minutes.
Cloud and container technologies are separately very exciting, as they promise to change the way resources are accessed and applications are deployed. Together, the possibilities are even more exciting. At Safe, we are incorporating and leveraging both of these technologies to enable FME to be deployed in ways that before we could only dream of.
We would very much like to hear your thoughts on this technology and tasks, and where you see it being valuable. We are also always happy to chat if, like us, you are excited by the possibilities shared here.
Explore more blog content headline

Getting Started with Cloud-Native Geospatial Data Formats


Data-Driven Marine Operations: 5 Ways to Generate Actionable Insights from Ship to Shore

Introducing FME Form 24.0: Redesigned User Experience for Focus and Consistency
